

Each strand of DNA is a polynucleotide composed of units called nucleotides. A nucleotide has three components: a sugar molecule, a phosphate group, and a nitrogenous base.
The sugar in DNA’s nucleotides is called deoxyribose—DNA is an abbreviation for deoxyribonucleic acid. RNA molecules use a different sugar, called ribose. Covalent bonds join the sugar of one nucleotide to the phosphate group of the next nucleotide, forming the DNA strand’s sugar-phosphate backbone.
A nitrogenous base is an organic molecule that contains nitrogen and has the chemical properties of a base. There are four nitrogenous bases that occur in DNA molecules: cytosine, guanine, adenine, and thymine (abbreviated as C, G, A, and T). RNA molecules contain cytosine, guanine, and adenine, but they have a different nitrogenous base, uracil (U) instead of thymine.
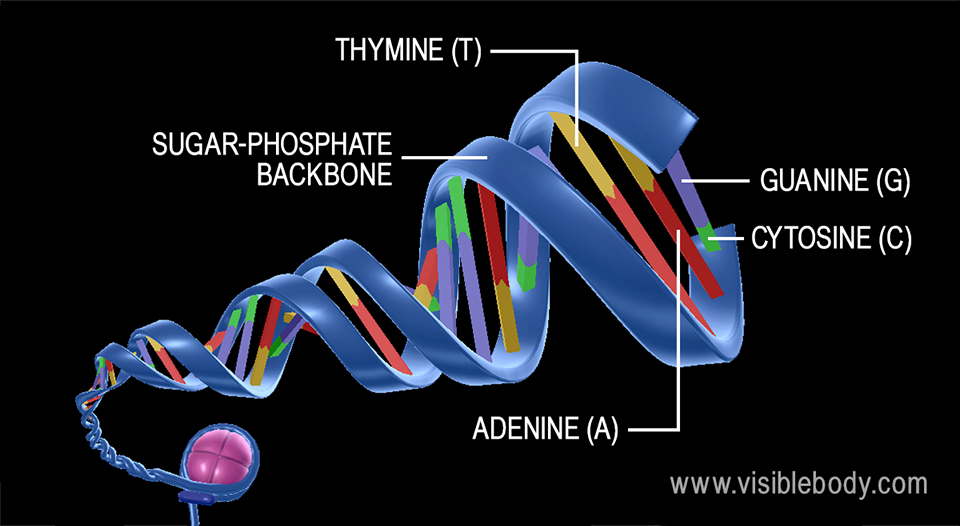
The sequence of nitrogenous bases on one strand of a DNA molecule’s double helix matches up in a particular way with the sequence on the other strand. Adenine pairs with thymine and cytosine pairs with guanine.
Why do the nitrogenous bases pair in this specific way? The bases on each strand are joined to the bases on the other strand with hydrogen bonds, but different bases have different chemical structures. Cytosine and thymine (and uracil in RNA) are pyrimidines, containing one ring. Adenine and guanine are purines, containing two rings. The pyrimidines pair with the purines: cytosine and guanine form three hydrogen bonds, and adenine and thymine form two.
Each strand of DNA is like a recipe book for synthesizing proteins. Certain sequences of nitrogenous bases along the strand encode particular RNA molecules. These sequences are called genes. mRNA molecules transcribed from genes are translated into proteins later.
Chromosomes can vary widely in their number of base pairs and genes. The longest chromosome in human cells, Chromosome 1, is around 249 million base pairs long and has between 2000 and 2100 distinct genes. Chromosome 21, the shortest human chromosome, consists of 48 million base pairs and contains between 200 and 300 genes. Overall, prokaryotic cells have shorter chromosomes with fewer genes. For example, the bacterium Carsonella rudii has only 159,662 base pairs and 182 genes in its entire genome.
Although genes get most of the credit for what DNA does, they make up only about 1% of DNA (in humans). Genes are separated from one another by sequences of nitrogenous bases that don’t provide instructions for RNA synthesis. These are called intergenic regions. Even within genes, there are regions of noncoding DNA called introns.
Noncoding regions of DNA are important because they provide binding sites for proteins that help activate or deactivate the process of transcription. They can also provide protection for the coding regions. For instance, telomeres consist of repetitive sequences that protect the genetic information on each DNA molecule from being damaged during cell division.
